Hadoop的高可用(HA)架构
Hadoop的前世今生
Hadoop是通过部署在多节点服务器,用来解决海量数据存储和计算的一种大数据框架。主要包括HDFS和MapReduce两方面。其中,HDFS负责解决海量数据的存储问题,MapReduce负责海量数据的计算问题。Hadoop包含一组不同的角色,分配到不同的服务器上,负责不同的功能任务,包括NameNode,DataNode等。NameNode节点负责维护整个集群的数据块位置等metaData元信息,DataNode称为节点机器,负责数据在节点上的存储。
NameNode上主要通过系统元数据FSImage和编辑日志edits来维护整个集群的数据信息(FSImage是整个集群的数据信息,包含HDFS文件系统中所有的目录和文件信息,位置等,而edits负责保存关于文件系统上的操作记录,后台进程会定期将edits合并到FSImage,以此来保证数据响应的实时性和数据的一致性)。在Hadoop1.0时代,只存在一个NameNode维护整个集群的数据元信息,此外,通过SecondaryNameNode角色来将edits合并到FSImage,最后将合并后的FSImage再更新回NameNode。(如果集群很大,一台NameNode无法装下,或者维护FSImage的压力过大,可以去查阅 HDFS Federation相关知识。简单思想就是,建立多个NameNode,每一个NameNode只负责管理一部分文件夹,根据请求的路径确定哪个NameNode去响应)
NameNode/SecondaryNameNode模式由于只有一个NameNode节点,有个很致命的问题在于,如果NameNode挂掉,那么整个集群也就瘫痪了,对一个生产系统来讲,这是不可接受的。那有没有什么办法能够提供高可用?在NameNode挂掉以后,不影响整个集群的服务?这就是Hadoop2.0后,高可用(HA)架构所要解决的问题。
由于现在整个大数据架构关系都非常密切,Hadoop,Yarn,Zookeepe等都密不可分,所以我会联系多个框架来讲HA架构。
HA整体架构图
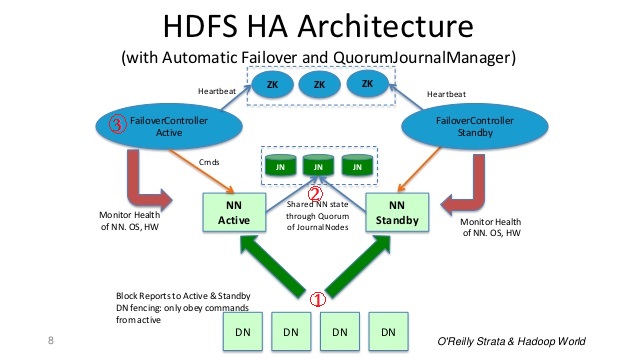
HA架构下,会有两个NameNode,一个处于Active状态,响应集群的请求,一个Stabdby状态,负责备用和合并edits,FSImage文件。当Active的NameNode挂掉以后,Standby状态的NameNode会马上切换为Active状态,响应集群请求。这样就实现了集群的高可用。同是两个NameNode之间会通过一组奇数个的JournalNode节点来维持数据同步。此外,通过FC线程(FailoverController)和zk(Zookeeper)集群来监控NameNode的状态和实现切换。
1. DN(DataNode)和NN(NameNode)之间通信
DN会同时将自身的数据块位置报告给所有的NN节点,但是只有处于Active的NN会对Client的请求进行响应。
2. NN之间数据同步
主备NN之间会通过一组奇数个数的JN(JournalNodes)节点来实现数据同步。当Active NN上需要对文件路径,文件等进行修改时,Active NN会将这个操作写到JN节点上(写入一半以上表示成功,所以需要奇数个JN节点),这就是edits日志。然后Standby NN会去JN上将edits同步下来,然后定时与FSImage进行合并,再将合并后的FSImage同步到Active NN上。
3.ZKFC(FailOverController)
ZKFC(Failover Controller)是一个ZK集群的客户端,该客户端包含三个进程:
- Health monitoring: 这个线程用于监控NN的状态是否正常,并定期向ZK集群发送心跳
- ZooKeeper session management: 当本地NN健康,会通过这个线程在zk集群上维持一个session。如果该NN是Active,那么zkfc还有持有一个“ephemeral”的锁,该锁只能有一个
- ZooKeeper-based election: 当Active NN出现问题,就会释放上条中说的那个独占锁。其他健康的NameNode发现没有其他NN占有独占锁,就会去抢占这个锁,一旦抢到,就会成为新的Active NN